Getting the best out of tomorrow’s HPC processors
Right now, High-Performance Computing (HPC) is going through the transition from the multi-core to the many-core era. This development comes with new challenges for application and system software developers - from modernizing legacy codes to making efficient use of the changing hardware toward developing new programming models for future applications. At ZIB, we are searching for solutions to these problems in close collaboration with leading industry partners. 
THE TREND
From Multi...
The multi-core era started when physical and technical limitations prevented further increases of the clock frequencies of single core CPUs. Instead, multiple cores where put into a single chip, which led to exponential growth in computing power. Current HPC multi-core processors have around one dozen cores. Leveraging their performance in an ap-plication requires software developers to assign tasks, which can be processed in parallel, to each core. Multi-cores are designed to perform well for wide variety of tasks, such as running desktop operating systems, office programs, multimedia applications, web services, data-bases, games, and scientific simulations.
...to Many-Cores
High-performance computing for science and engineering deals with very specific applications exposing common character-istics. Many-core processors are desig-ned specifically for such workloads. This allows for the further improvement of computing power within the current limitations like chip area and power consumption. Many-cores have multiple dozens of rather simple computecores that are optimized for numerical computations. The increased chip area is spent on arithmetical units for floating-point computations instead of processor logic and general-purpose optimizations.
The development of many-cores started when graphics processors (GPUs) became freely programmable. Similarities between computer games and scientific simulations allowed scientists to exploit the processing power of the graphics hardware to compute scientific problems. GPU manufactures quickly recognized the new market and created general-purpose GPUs (GPGPUs) specifically for accelerating HPC systems. Today, GPGPUs are an integral part of many of the fastest systems on the planet. However, GPGPUs are mere accelerators that reside in a host system, just like a graphics card in a PC. Only compute-intensive program parts called kernels are offloaded from the host CPU to the GPGPU for faster processing. To utilize a modern GPGPU, a problem must be partitioned into thousands of small tasks that are computed in parallel.
Alongside the GPGPU trend, Intel defined a Many Integrated Cores (MIC) architecture, which is more similar to x86 multi-cores. The first MIC implementation, the Xeon Phi coprocessor (Knights Corner), has around 60 cores that draw their computing power from vector processing units. Enabling vectorization in a program, especially for legacy codes, is a major problem we face and is closely connected to memory access optimization.
Intel(R) Xeon Phi(TM) (Knights Corner) coprocessor.
VECTOR PROCESSING IN THE PAST, TODAY, AND TOMORROW
From the early 1970s to the 1990s, vector processors were rated the quasi architectural standard for the design of supercomputers.
Representatives like the legendary Cray 1M, the Cray X-MP, and later the Y-MP have been installed at Zuse Institute Berlin. The latter was operated until 1995. However, the increasing performance and the decreasing prices of conventional processors triggered (with a few exceptions) the end of the vector processor era in the mid-1990s. Around the year 2000, vector processing re-emerged in the form of short vector SIMD units, starting with SSE and AltiVec. Current multi-core CPUs can perform four double-precision operations at once using AVX or AVX2. The Intel Xeon Phi many-core coprocessor can do eight per vector unit of which it has one per core.

Development of vector processing: transition from vector to multi-core to many-core processors and GPGPUs. Around the year 2000, short vector SIMD units were integrated into the standard CPUs.
Auto-Vectorising Compilers
Modern optimizing compilers are not only capable of inserting SIMD vector instructions when explicitly told to by the programmer but manage to introduce SIMD execution even into larger code segments on their own.
Auto-vectorization by the compiler turns out to be satisfactory for (highly) regular data processing – for example, in dense linear algebra operations with its regular loop structures. Many other cases – that is, with more complex loops - require explicit vectorization, meaning the introduction of compiler directives into the code in order to give additional information to the compiler or manual vectorization. While the latter is notably intrusive to the code, the directive based approach is not so at first sight. However, for codes that are not prepared for SIMD at all, heavy code rewriting together with a careful selection of the most appropriate compiler directives is required. Additionally, deficiencies to present specific optimization strategies to the compiler may render the directive based approach impractical in certain situations. In these cases, manual vector coding can be considered as the a resort.
IMPACT ON SIMD OPTIMIZATION OF APPLICATION PERFORMANCE

Application performance gain due to SIMD vectorization. The application has been executed on a Xeon Phi cluster using up to eight compute nodes. Only some hotspots were optimized for SIMD; that is, there is further potential for additional speedups over the reference execution.
As the compiler vendors are aware of these issues, auto-vectorization capabilities are pushed strongly. Besides loop transformations and code reorganization, the current research has its focus on managing irregularities within loops to approach SIMD execution. Emerging SIMD instruction sets therefore will cover masked SIMD operations – for example,to enable the separation of divergent execution paths. A further feature programmers can draw on when optimizing their codes for SIMD is SIMD-enabled functions. By means of specific directives, the compiler can be encouraged to expand scalar function definitions to work on vector arguments and, hence, be callable from within vectorizable loops. Investigations regarding the usability of these new features are carried out within ZIB’s activities at the Intel Parallel Computing Center (IPCC).
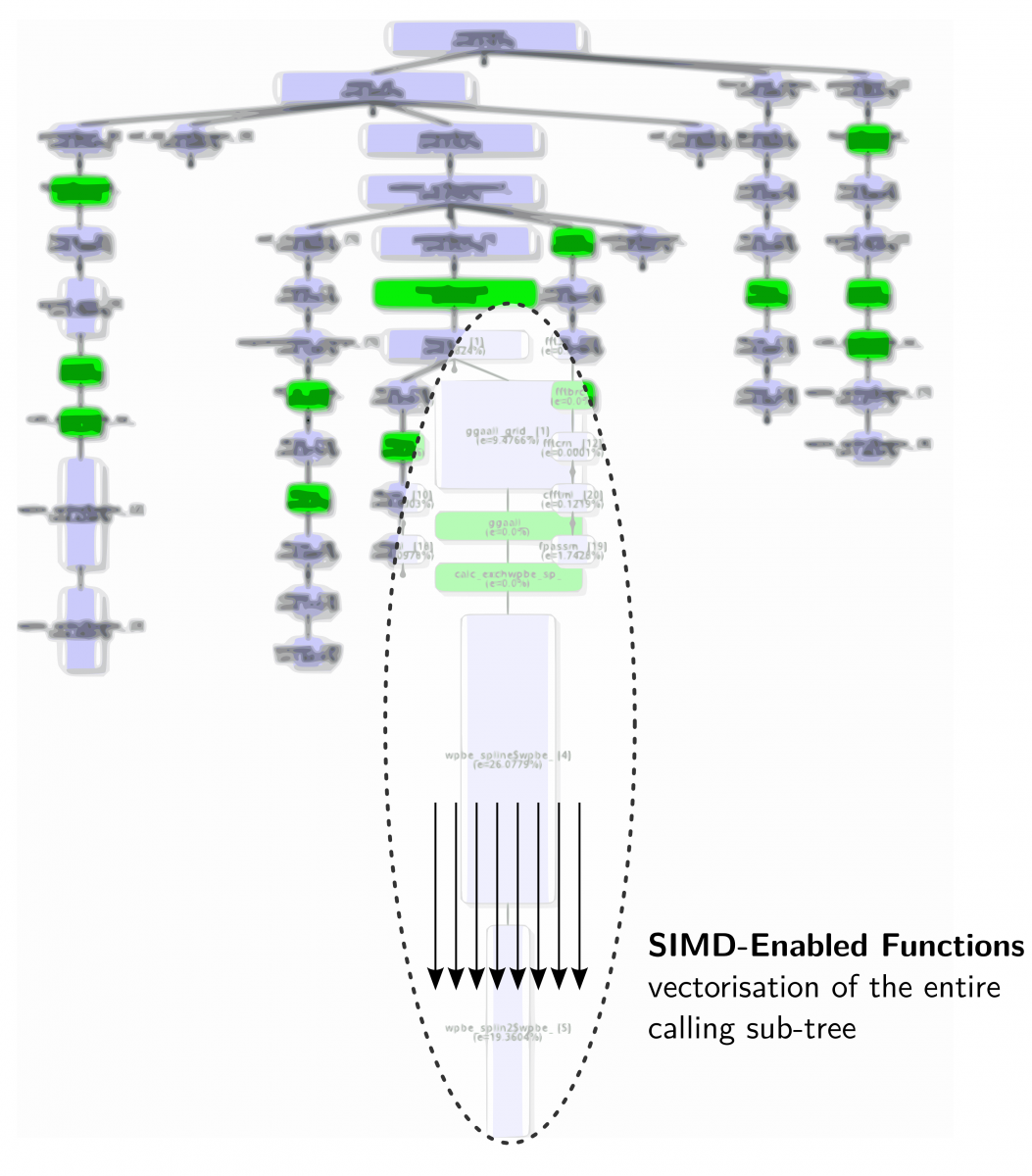
Vectorisation along the calling tree of an application using the SIMD-enabled functions feature.
MANUALVECTORIZATION AND MEMORY LAYOUT
Besides automatic vectorization by the compiler, there are also means to manually vectorize application code. For instance, the OpenCL C programming language provides vector types.
These types allow for operation with vectors of multiple - for instance eight - floating point numbers in parallel. Arithmetic operations with such vectors can then be directly mapped to the corresponding instructions of the hardware. For conventional languages like C, most compilers offer intrinsics, which are low-level operations that allow directly programming of the hardware’s vector units. For the C++ language, there are libraries that encapsulate those intrinsics for different hardware platforms behind a common interface. This approach leads to more portable code. The advantage of manual vectorization is control over the applied vectorization strategy by the programmer. This allows for the opitmization of the memory layout for contiguous load and store operations to and from the processor’s vector registers.

Transition toward a vectorization-friendly memory layout.
We used the GPU-HEOM code to conduct a case study with different vectorization approaches. GPU-HEOM uses the Hierarchical Equations of Motion (HEOM) method to simulate the energy transfer in natural and artificial photoactive systems. We found the memory layout to be the most important factor for efficient vectorization on both multi- and many-cores.
Together with other optimizations, we could improve the performance of the Hexciton computation of HEOM by up to 6.3 times on the Xeon Phi coprocessor. The continuation of this work was successfully proposed as an interdisciplinary DFG (German Research Foundation) project that starts in early 2015.
Research Center for Many-Core High-Performance Computing
Since 2013, ZIB has been operating the Research Center for Many-Core High-Perfor-mance Computing, which was established together with Intel as one of the first Intel Parallel Computing Centers (IPPC) in Europe. The goal is to modernize existing HPC codes, especially those relevant for the HLRN user community, and to develop novel algorithms and programming models for the many-core era. The IPCC program provides ZIB researchers with early access to upcoming hardware products and allows for close collaboration with Intel engineers.

Vectorization
We adapt both legacy and modern codes to exploit the vector capabilities of today’s and tomorrow’s many-cores. Our focus is on generic but close-to-hardware vector coding to get sustainable performance out of upcoming processor generations. For that, we draw on auto-vectorizer capabilities where possible and switch to SIMD libraries if the compiler hits the wall.
Concurrent Kernel Offloading
We not only have large-scale computations on the screen, butwe also aim to have small-scale workloads benefit from multi- and many-core performance. If a single problem instance cannot utilize all computing resources, why not runing multiples of them simultaneously? Concurrent kernel offloading approaches share multi- and many-cores to increase the overall application throughput.
Efficient Intra- and Inter-Node Offloading
We developed an offloading framework that focuses on efficiency and on unifying local (intra-node) offloading and remote (inter-node) offloading within a single programming interface. This allows for fine-grained offloading and scaling applications beyond the many-core coprocessors installed in a single node.
Vectorization
Besides modern codes that can be designedwith fine-grained parallelism and vectorization in mind directly from the beginning, legacy codes often do not fit the new multi- and many-core processors without adaptations. Particularly, many of the complex community codes from the different fields of science have their origins some decades ago, and their design originates from the very different architectural features found in processors up to now. For instance, codes that once were written for vector processors have been extended with new functionalities, but not necessarily with vector processors as the target platform in mind. As SIMD vectorization has already experienced a revival on the current multi-cores. For many-cores it is an absolute necessity, among other adaptations, to redesign certain codes so as to exploit SIMD execution.
Optimizing an application for vector processing may cover the whole range from redesigning algorithmic elements to meet SIMD requirements, to choosing appropriate data layouts, to finally writing down the code in a SIMD-friendly way. For the latter, we focus on generic vector programming so that codes are portable across different platforms. The latter is mainly achieved by using compiler directives and vector libraries that encapsulate assembly or SIMD intrinsic functions in the C/C++ programming language.
Concurrent Kernel Offloading
The concurrent kernel offload (CKO) mode approaches the inherent underutilization of modern many-core processors when workloads are too small to exploit the available computing resources on their own. Instead of processing only a single problem instance, multiples of them are handled concurrently, thereby sharing the many-core processor for an increased overall load. Within the IPCC activities at ZIB, the CKO feature has been integrated into the GLAT program so as to leverage the immense computing power of the Intel Xeon Phi coprocessor for the simulation of small drug-like molecules. One of the key insights in that respect is the necessity to partition the many-core processor appropriately so that concurrent computations do not interfere with each other. Results of extensive studies regarding CKO on the Xeon Phi coprocessor have found their way into the book High Performance Parallelism Pearls by J. Jeffers and J. Reinders.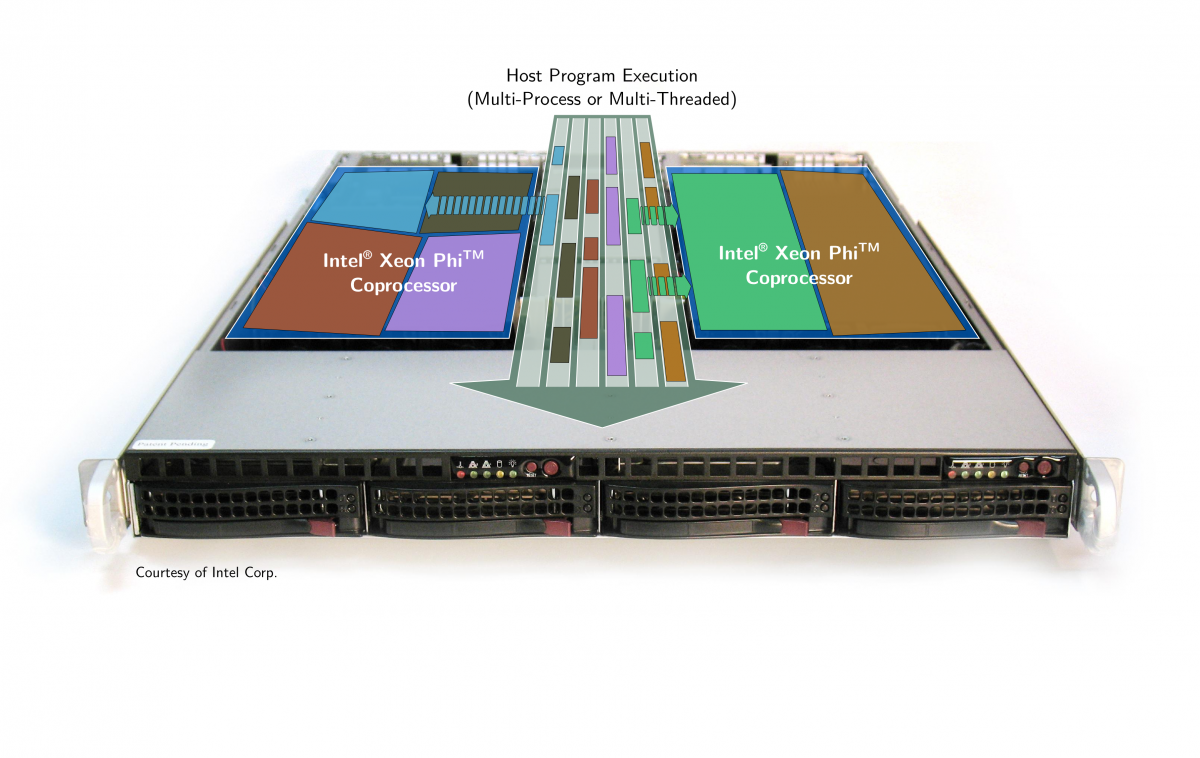
Concurrent kernel offloading from within a multi-threaded or multi-process host application. The two Xeon Phi coprocessors are partitioned so that off-loads from different host threads or processes do not interfere.
Efficient Intra- and Inter-node Offloading
Current many-core solutions – that is, GPGPUs and the Intel Xeon Phi – are accelerators that run inside a host system that uses one or more multi-core CPUs. The standard programming model for this heterogeneous system architecture is offloading, where only compute-intensive portions of the program are computed on the accelerator. These compute kernels can be computed faster on the accelerator, but the process of offloading takes time and resources by itself, which adds additional costs to the program execution. For instance, input data must be transferred to the accelerator’s memory, the code for the computation must be transferred and executed in coordination with the host, and finally the results must be transferred back to the host. Only program parts where the gain over-compensates the costs are suitable for offloading. Less overhead means more potential for offloading even fine-grained tasks. We developed the HAM-Offload framework with the goal to minimize the offloading costs and thus make many-cores accessible for a wider class of applications. By utilizing modern C++ meta-programming techniques, HAM-Offload can reduce the cost per offload by a factor of 28 compared with Intel’s Language Extensions for Offload (LEO). For a small problem instance of GLAT that causes fine-grained offloads, this translates into an application speedup factor of two.
Existing solutions are also limited to intra-node, or local, offloading within a single node. Offloading tasks to remote accelerators over a network requires the usage of another programming model, like the Message Passing Interface (MPI). HAM-Offload unifies local and remote offloading, and even allows reverse offloading from a many-core coprocessor towards a multi-core host system. This is completely transparent for the programmer, who uses a single API (Application Programming Interface) to put work on local and remote targets. Behind the scenes, HAM-Offload uses MPI for network communication which ensures compatibility with most system installations. For existing offload applications, this allows to scale beyond the limited number of local coprocessors without introducing explicit inter-node communication into the application code. We were able to demonstrate this for the GLAT application using the coprocessors of 16 nodes instead of just one. Inter-node, or remote, offloading with HAM-Offload causes only half as much offloading costs, as Intel LEO does for local offloads.

Remote offloading using a hybrid approach combining MPI and Intel LEO (Language Extension for Offload) vs. HAM-Off-load. The box labeled MIC is the remote Xeon Phi™ accelerator.
Collaborations
ZIB researchers collaborate with leading industrial partners in tackling challenges associated with the transition to next-generation, highly parallel computer architectures.
In addition to the IPCC activities, we are working with Cray on the adoption of new technologies including many-core processor nodes with state-of-the-art interconnects and nonvolatile memory in HPC and Big Data analytics workloads. For the evaluation and optimization of different workloads, we operate a Cray XC40 Test and Development System (TDS) currently comprising 16 nodes with Xeon Phi coprocessors (KNC) and eight Cray DataWarp (SSD) nodes. This TDS will be upgraded to 80 nodes with the Intel Knights Landing (KNL) processor in 2016.
ZIB continues to support training activities to help developers in the HLRN community in their migration and optimization efforts. As a member of the Intel Xeon Phi User’s Group (IXPUG) Steering Committee, ZIB is supporting world-wide dissemination activities in the area many-core computing.
